Análisis de Ecuaciones Estructurales
Los Modelos de Ecuaciones Estructurales son una familia de modelos estadísticos multivariantes que permiten estimar el efecto y las relaciones entre múltiples variables tanto observadas como latentes.
En esta guía trabajaremos con la Encuesta de Bienestar Social. Construiremos un modelo de ecuaciones estructurales que busca observar el efecto de la seguridad ciudadana percibida en el barrio sobre la salud mental, en particular la sintomatología depresiva, ambas medidas como variables latentes a partir de escalas. Además se incluirán como co-varaibles el quintil de ingreso autónomo, la zona (urbano/rural), el sexo, la edad, la percepción de haber recibido maltrato y la satisfacción con la vida social.
Las escalas utilizadas pueden observarse a continuación:

# Carga las bibliotecas necesarias
library(haven)
library(MVN)
library(dplyr)
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
library(lavaan)
## This is lavaan 0.6-15
## lavaan is FREE software! Please report any bugs.
library(semPlot)
library(semTable)
Las bibliotecas necesarias son haven para la importación de datos, MVN para la evaluación de la normalidad multivariante, lavaan para realizar análisis de senderos, semPlot para la visualización del modelo y semTable para la presentación de los resultados.
# Importar datos
temp <- tempfile() #Creamos un archivo temporal
download.file("https://observatorio.ministeriodesarrollosocial.gob.cl/storage/docs/bienestar-social/Base_de_datos_EBS_2021_SPSS.sav.zip",temp) #descargamos los datos
data <- haven::read_sav(unz(temp, "Base de datos EBS 2021 SPSS.sav")) #cargamos los datos
unlink(temp); remove(temp) #eliminamos el archivo temporal
Los datos se importan de una URL utilizando la función read_sav de la biblioteca haven.
# Tratamiento de los datos
ebs <- data %>%
mutate(zona = ifelse(zona == 2, 1, 0),
sexo = ifelse(sexo == 2, 1, 0)) %>%
select(qaut, zona, sexo,
sm_1 = b9_1,
sm_2 = b9_2,
sm_3 = b9_3,
sm_4 = b9_4,
seg_1 = h4_1,
seg_2 = h4_2,
seg_3 = h4_3,
seg_4 = h4_4,
maltrato = e5,
social = a3_5,
edad = l1)
Luego realizamos transformaciones necesarias a los datos, incluyendo la re codificación de variables dicotómicas, la selección de las variables a utilizar y la reasignación de sus nombres para facilitar su interpretabilidad.
# Comprobación de supuestos
dim(ebs)
## [1] 10921 14
cor(ebs,use = "complete.obs")
## qaut zona sexo sm_1 sm_2
## qaut 1.00000000 -0.13743599 -0.09809966 -0.05658119 -0.091917460
## zona -0.13743599 1.00000000 -0.01684651 -0.01159373 -0.012206651
## sexo -0.09809966 -0.01684651 1.00000000 0.14519203 0.171028981
## sm_1 -0.05658119 -0.01159373 0.14519203 1.00000000 0.595251943
## sm_2 -0.09191746 -0.01220665 0.17102898 0.59525194 1.000000000
## sm_3 -0.03966184 -0.04208925 0.15938914 0.43551702 0.545353966
## sm_4 -0.06987665 -0.01639299 0.08372739 0.37163443 0.451713539
## seg_1 0.07760156 0.08631437 -0.09896644 -0.12819538 -0.141548177
## seg_2 0.07208810 0.08053765 -0.12496411 -0.13968095 -0.151978986
## seg_3 0.05207230 0.13363871 -0.21053438 -0.13815466 -0.149582425
## seg_4 0.06286000 0.02798475 -0.03844811 -0.11081643 -0.116751646
## maltrato 0.01442646 -0.03554225 0.04210078 0.21228918 0.274600973
## social -0.01815819 0.02874349 -0.09035951 -0.19197650 -0.242382078
## edad -0.01747121 0.04776623 0.03457414 -0.06689464 -0.002735007
## sm_3 sm_4 seg_1 seg_2 seg_3
## qaut -0.03966184 -0.06987665 0.07760156 0.07208810 0.05207230
## zona -0.04208925 -0.01639299 0.08631437 0.08053765 0.13363871
## sexo 0.15938914 0.08372739 -0.09896644 -0.12496411 -0.21053438
## sm_1 0.43551702 0.37163443 -0.12819538 -0.13968095 -0.13815466
## sm_2 0.54535397 0.45171354 -0.14154818 -0.15197899 -0.14958242
## sm_3 1.00000000 0.51175608 -0.14221919 -0.14859112 -0.15962056
## sm_4 0.51175608 1.00000000 -0.12832860 -0.13315958 -0.10844160
## seg_1 -0.14221919 -0.12832860 1.00000000 0.70750583 0.53030876
## seg_2 -0.14859112 -0.13315958 0.70750583 1.00000000 0.55080948
## seg_3 -0.15962056 -0.10844160 0.53030876 0.55080948 1.00000000
## seg_4 -0.11531715 -0.10126633 0.39163209 0.42155952 0.24580693
## maltrato 0.26703281 0.21658963 -0.09833619 -0.09210678 -0.09275361
## social -0.20593843 -0.16031876 0.09011646 0.09482417 0.10139417
## edad -0.08447826 -0.01770926 -0.03966969 -0.04176572 -0.04338797
## seg_4 maltrato social edad
## qaut 0.06286000 0.01442646 -0.01815819 -0.017471206
## zona 0.02798475 -0.03554225 0.02874349 0.047766225
## sexo -0.03844811 0.04210078 -0.09035951 0.034574136
## sm_1 -0.11081643 0.21228918 -0.19197650 -0.066894641
## sm_2 -0.11675165 0.27460097 -0.24238208 -0.002735007
## sm_3 -0.11531715 0.26703281 -0.20593843 -0.084478256
## sm_4 -0.10126633 0.21658963 -0.16031876 -0.017709262
## seg_1 0.39163209 -0.09833619 0.09011646 -0.039669694
## seg_2 0.42155952 -0.09210678 0.09482417 -0.041765719
## seg_3 0.24580693 -0.09275361 0.10139417 -0.043387969
## seg_4 1.00000000 -0.09958077 0.09665035 -0.048929669
## maltrato -0.09958077 1.00000000 -0.15603843 -0.142186453
## social 0.09665035 -0.15603843 1.00000000 -0.027988251
## edad -0.04892967 -0.14218645 -0.02798825 1.000000000
summary(ebs)
## qaut zona sexo sm_1
## Min. :1.000 Min. :0.0000 Min. :0.0000 Min. :1.000
## 1st Qu.:2.000 1st Qu.:0.0000 1st Qu.:0.0000 1st Qu.:1.000
## Median :3.000 Median :0.0000 Median :1.0000 Median :2.000
## Mean :2.852 Mean :0.1478 Mean :0.5776 Mean :1.905
## 3rd Qu.:4.000 3rd Qu.:0.0000 3rd Qu.:1.0000 3rd Qu.:2.000
## Max. :5.000 Max. :1.0000 Max. :1.0000 Max. :4.000
## sm_2 sm_3 sm_4 seg_1 seg_2
## Min. :1.000 Min. :1.000 Min. :1.00 Min. :1.000 Min. :1.00
## 1st Qu.:1.000 1st Qu.:1.000 1st Qu.:1.00 1st Qu.:2.000 1st Qu.:3.00
## Median :2.000 Median :2.000 Median :1.00 Median :4.000 Median :4.00
## Mean :1.798 Mean :1.933 Mean :1.61 Mean :3.296 Mean :3.48
## 3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:2.00 3rd Qu.:4.000 3rd Qu.:4.00
## Max. :4.000 Max. :4.000 Max. :4.00 Max. :5.000 Max. :5.00
## seg_3 seg_4 maltrato social
## Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.000
## 1st Qu.:1.000 1st Qu.:4.000 1st Qu.:1.000 1st Qu.:3.000
## Median :2.000 Median :4.000 Median :1.000 Median :4.000
## Mean :2.432 Mean :4.191 Mean :1.818 Mean :3.446
## 3rd Qu.:4.000 3rd Qu.:5.000 3rd Qu.:2.000 3rd Qu.:4.000
## Max. :5.000 Max. :5.000 Max. :5.000 Max. :5.000
## edad
## Min. : 18.00
## 1st Qu.: 31.00
## Median : 46.00
## Mean : 46.38
## 3rd Qu.: 60.00
## Max. :100.00
mvn(ebs,mvnTest = "mardia")
## $multivariateNormality
## Test Statistic p value Result
## 1 Mardia Skewness 28495.0914013263 0 NO
## 2 Mardia Kurtosis 57.4028252884527 0 NO
## 3 MVN <NA> <NA> NO
##
## $univariateNormality
## Test Variable Statistic p value Normality
## 1 Anderson-Darling qaut 371.0977 <0.001 NO
## 2 Anderson-Darling zona 3255.9843 <0.001 NO
## 3 Anderson-Darling sexo 2024.9364 <0.001 NO
## 4 Anderson-Darling sm_1 866.2729 <0.001 NO
## 5 Anderson-Darling sm_2 940.7807 <0.001 NO
## 6 Anderson-Darling sm_3 855.3259 <0.001 NO
## 7 Anderson-Darling sm_4 1393.0796 <0.001 NO
## 8 Anderson-Darling seg_1 440.2020 <0.001 NO
## 9 Anderson-Darling seg_2 526.7011 <0.001 NO
## 10 Anderson-Darling seg_3 537.6820 <0.001 NO
## 11 Anderson-Darling seg_4 933.9012 <0.001 NO
## 12 Anderson-Darling maltrato 1138.8198 <0.001 NO
## 13 Anderson-Darling social 788.7672 <0.001 NO
## 14 Anderson-Darling edad 92.4992 <0.001 NO
##
## $Descriptives
## n Mean Std.Dev Median Min Max 25th 75th Skew
## qaut 10921 2.8515704 1.3563173 3 1 5 2 4 0.1366615
## zona 10921 0.1477887 0.3549066 0 0 1 0 0 1.9846296
## sexo 10921 0.5776028 0.4939637 1 0 1 0 1 -0.3141756
## sm_1 10921 1.9046791 0.9158640 2 1 4 1 2 0.9380134
## sm_2 10921 1.7978207 0.8599551 2 1 4 1 2 1.0707137
## sm_3 10921 1.9333394 0.9159490 2 1 4 1 2 0.9062407
## sm_4 10921 1.6102921 0.8973610 1 1 4 1 2 1.4847401
## seg_1 10921 3.2964930 1.1881572 4 1 5 2 4 -0.4097997
## seg_2 10921 3.4804505 1.1359137 4 1 5 3 4 -0.5908154
## seg_3 10921 2.4317370 1.3132656 2 1 5 1 4 0.4278456
## seg_4 10921 4.1913744 0.9508059 4 1 5 4 5 -1.4240930
## maltrato 10921 1.8177823 1.1027516 1 1 5 1 2 1.2226045
## social 10921 3.4462046 1.0846348 4 1 5 3 4 -0.6017786
## edad 10921 46.3780789 17.6844645 46 18 100 31 60 0.1712371
## Kurtosis
## qaut -1.1938606
## zona 1.9389321
## sexo -1.9014678
## sm_1 0.1654643
## sm_2 0.6582041
## sm_3 0.1208467
## sm_4 1.3131532
## seg_1 -0.7505433
## seg_2 -0.4457976
## seg_3 -1.0741905
## seg_4 1.9957658
## maltrato 0.5531274
## social -0.5816152
## edad -0.9558384
Aquí se revisan varios supuestos antes de ajustar el modelo de ecuaciones estructurales.
- dim(datos) muestra las dimensiones de los datos
- cor(datos,use = “complete.obs”) muestra las correlaciones entre variables
- summary(datos) ofrece un resumen estadístico de las variables
- mvn(datos) evalúa la normalidad multivariante, que es un supuesto clave en el análisis de ecuaciones estructurales, en particular para es uso del método de estimación de máxima verosimilitud.
Especificación y estimación del modelo
Para especificar el modelo, debemos definir las variables que lo componen y sus relaciones. Para integrar esto en R, en el paquete lavaan, debemos expresar nuestro modelo de ecuaciones estructurales en la sintaxis propia de dicho paquete:
| Sintaxis | Comando | Ejemplo |
|---|---|---|
| ~ | Regresar en | Regresar B sobre A: B ~ A |
| ~~ | (Co)varianza | Varianza de A: A ~~ A |
| =~ | Definir variable latente | Definir Definir Factor 1 por A-D: F1 =~ A + B + C + D |
| := | Definir parámetro fuera del modelo | Definir parámetro u2 como doble del cuadrado de u: u2 := 2*(u^2) |
| * | Etiquetar parámetros (etiqueta antes de símbolo) | Etiquetar la regresión de Z sobre X como b: Z ~ b*X |
# Especificar y ajustar el modelo de senderos
mod_sem <- 'SM =~ sm_1+sm_2+sm_3+sm_4
SEG =~ seg_1+seg_2+seg_3+seg_4
SM ~ qaut+zona+sexo+edad+SEG+maltrato+social'
ajus_sem <- sem(mod_sem, data=ebs)
Aquí, el primer bloque define las variables latentes (SM y SEG) como indicadas por sus respectivas variables observadas (sm_1, sm_2, etc. para SM y seg_1, seg_2, etc. para SEG). El operador =~ se utiliza para definir las variables latentes.
El segundo bloque especifica la ecuación estructural, donde la variable latente SM es modelada en función de varias otras variables y la variable latente SEG. El operador ~ se utiliza para definir las relaciones de regresión en el modelo.
Finalmente, sem() es la función que ajusta el modelo de ecuaciones estructurales. Acepta la especificación del modelo y los datos en los que se basa.
# Resumen de los resultados del modelo de ecuaciones estructurales
summary(ajus_sem, fit.measures = T, standardized = T, rsquare = T, modindices = T)
## lavaan 0.6.15 ended normally after 33 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 23
##
## Number of observations 10921
##
## Model Test User Model:
##
## Test statistic 2068.190
## Degrees of freedom 61
## P-value (Chi-square) 0.000
##
## Model Test Baseline Model:
##
## Test statistic 31268.376
## Degrees of freedom 76
## P-value 0.000
##
## User Model versus Baseline Model:
##
## Comparative Fit Index (CFI) 0.936
## Tucker-Lewis Index (TLI) 0.920
##
## Loglikelihood and Information Criteria:
##
## Loglikelihood user model (H0) -110316.491
## Loglikelihood unrestricted model (H1) NA
##
## Akaike (AIC) 220678.983
## Bayesian (BIC) 220846.847
## Sample-size adjusted Bayesian (SABIC) 220773.756
##
## Root Mean Square Error of Approximation:
##
## RMSEA 0.055
## 90 Percent confidence interval - lower 0.053
## 90 Percent confidence interval - upper 0.057
## P-value H_0: RMSEA <= 0.050 0.000
## P-value H_0: RMSEA >= 0.080 0.000
##
## Standardized Root Mean Square Residual:
##
## SRMR 0.052
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## SM =~
## sm_1 1.000 0.618 0.678
## sm_2 1.109 0.017 64.094 0.000 0.685 0.803
## sm_3 1.027 0.017 59.514 0.000 0.634 0.696
## sm_4 0.861 0.016 52.399 0.000 0.531 0.595
## SEG =~
## seg_1 1.000 0.975 0.821
## seg_2 1.009 0.012 81.513 0.000 0.984 0.866
## seg_3 0.854 0.013 65.602 0.000 0.833 0.634
## seg_4 0.460 0.010 47.436 0.000 0.449 0.472
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## SM ~
## qaut -0.036 0.004 -7.956 0.000 -0.058 -0.079
## zona -0.005 0.017 -0.301 0.763 -0.008 -0.003
## sexo 0.186 0.012 14.998 0.000 0.301 0.149
## edad -0.001 0.000 -3.263 0.001 -0.002 -0.032
## SEG -0.100 0.007 -14.864 0.000 -0.159 -0.159
## maltrato 0.162 0.006 27.805 0.000 0.263 0.290
## social -0.126 0.006 -21.816 0.000 -0.204 -0.222
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .sm_1 0.448 0.008 58.825 0.000 0.448 0.540
## .sm_2 0.259 0.006 42.179 0.000 0.259 0.356
## .sm_3 0.427 0.007 57.106 0.000 0.427 0.515
## .sm_4 0.516 0.008 64.426 0.000 0.516 0.646
## .seg_1 0.461 0.011 41.886 0.000 0.461 0.326
## .seg_2 0.322 0.010 31.809 0.000 0.322 0.250
## .seg_3 1.031 0.016 65.183 0.000 1.031 0.598
## .seg_4 0.702 0.010 70.305 0.000 0.702 0.777
## .SM 0.297 0.008 35.519 0.000 0.780 0.780
## SEG 0.951 0.020 47.068 0.000 1.000 1.000
##
## R-Square:
## Estimate
## sm_1 0.460
## sm_2 0.644
## sm_3 0.485
## sm_4 0.354
## seg_1 0.674
## seg_2 0.750
## seg_3 0.402
## seg_4 0.223
## SM 0.220
##
## Modification Indices:
##
## lhs op rhs mi epc sepc.lv sepc.all sepc.nox
## 1 SM =~ seg_1 0.003 0.001 0.001 0.000 0.000
## 2 SM =~ seg_2 0.074 -0.004 -0.002 -0.002 -0.002
## 3 SM =~ seg_3 57.686 -0.143 -0.088 -0.067 -0.067
## 4 SM =~ seg_4 31.511 -0.084 -0.052 -0.055 -0.055
## 5 SEG =~ sm_1 0.087 -0.002 -0.002 -0.003 -0.003
## 6 SEG =~ sm_2 8.810 0.022 0.021 0.025 0.025
## 7 SEG =~ sm_3 3.612 -0.015 -0.015 -0.016 -0.016
## 8 SEG =~ sm_4 2.671 -0.014 -0.013 -0.015 -0.015
## 9 sm_1 ~~ sm_2 500.892 0.150 0.150 0.441 0.441
## 10 sm_1 ~~ sm_3 171.235 -0.083 -0.083 -0.191 -0.191
## 11 sm_1 ~~ sm_4 76.044 -0.052 -0.052 -0.108 -0.108
## 12 sm_1 ~~ seg_1 1.307 0.006 0.006 0.014 0.014
## 13 sm_1 ~~ seg_2 0.000 0.000 0.000 0.000 0.000
## 14 sm_1 ~~ seg_3 0.914 -0.007 -0.007 -0.010 -0.010
## 15 sm_1 ~~ seg_4 1.711 -0.008 -0.008 -0.014 -0.014
## 16 sm_2 ~~ sm_3 110.320 -0.072 -0.072 -0.218 -0.218
## 17 sm_2 ~~ sm_4 141.598 -0.071 -0.071 -0.195 -0.195
## 18 sm_2 ~~ seg_1 1.831 0.007 0.007 0.019 0.019
## 19 sm_2 ~~ seg_2 0.655 0.004 0.004 0.013 0.013
## 20 sm_2 ~~ seg_3 0.006 -0.001 -0.001 -0.001 -0.001
## 21 sm_2 ~~ seg_4 0.039 -0.001 -0.001 -0.002 -0.002
## 22 sm_3 ~~ sm_4 500.652 0.134 0.134 0.286 0.286
## 23 sm_3 ~~ seg_1 0.001 0.000 0.000 0.000 0.000
## 24 sm_3 ~~ seg_2 1.003 0.005 0.005 0.014 0.014
## 25 sm_3 ~~ seg_3 13.786 -0.027 -0.027 -0.041 -0.041
## 26 sm_3 ~~ seg_4 0.839 -0.005 -0.005 -0.010 -0.010
## 27 sm_4 ~~ seg_1 2.185 -0.009 -0.009 -0.018 -0.018
## 28 sm_4 ~~ seg_2 0.853 -0.005 -0.005 -0.012 -0.012
## 29 sm_4 ~~ seg_3 7.610 0.021 0.021 0.029 0.029
## 30 sm_4 ~~ seg_4 0.913 -0.006 -0.006 -0.010 -0.010
## 31 seg_1 ~~ seg_2 55.608 -0.164 -0.164 -0.426 -0.426
## 32 seg_1 ~~ seg_3 24.391 0.069 0.069 0.100 0.100
## 33 seg_1 ~~ seg_4 1.434 0.009 0.009 0.017 0.017
## 34 seg_2 ~~ seg_3 1.191 0.016 0.016 0.027 0.027
## 35 seg_2 ~~ seg_4 25.475 0.039 0.039 0.082 0.082
## 36 seg_3 ~~ seg_4 82.981 -0.082 -0.082 -0.096 -0.096
## 37 qaut ~ SM 81.653 -1.274 -0.787 -0.580 -0.580
## 38 qaut ~ SEG 81.653 0.128 0.125 0.092 0.092
## 39 zona ~ SM 123.825 -0.412 -0.254 -0.717 -0.717
## 40 zona ~ SEG 123.823 0.041 0.040 0.114 0.114
## 41 sexo ~ SM 150.496 0.633 0.391 0.791 0.791
## 42 sexo ~ SEG 150.494 -0.064 -0.062 -0.125 -0.125
## 43 edad ~ SM 39.129 11.518 7.114 0.402 0.402
## 44 edad ~ SEG 39.127 -1.157 -1.128 -0.064 -0.064
## 45 SEG ~ SM 389.083 -0.729 -0.461 -0.461 -0.461
## 46 SEG ~ qaut 74.789 0.064 0.066 0.089 0.066
## 47 SEG ~ zona 110.649 0.299 0.306 0.109 0.306
## 48 SEG ~ sexo 222.470 -0.304 -0.312 -0.154 -0.312
## 49 SEG ~ edad 26.461 -0.003 -0.003 -0.053 -0.003
## 50 SEG ~ maltrato 135.752 -0.106 -0.109 -0.120 -0.109
## 51 SEG ~ social 134.310 0.108 0.110 0.120 0.110
## 52 maltrato ~ SM 103.719 1.156 0.714 0.648 0.648
## 53 maltrato ~ SEG 103.719 -0.116 -0.113 -0.103 -0.103
## 54 social ~ SM 69.845 -0.940 -0.580 -0.535 -0.535
## 55 social ~ SEG 69.845 0.094 0.092 0.085 0.085
La función summary() proporciona un resumen de los resultados, incluyendo varias medidas de ajuste, las cargas factoriales de las variables latentes medidas coeficientes estandarizados, los coeficientes de determinación (R^2) y los índices de modificación.
En primer lugar debemos ver si el ajuste global del modelo es apropiado.
Test de chi cuadrado: Este es un test que compara el modelo estimado con el modelo de saturación (uno que ajusta perfectamente los datos). Un resultado no significativo (p>0.05) sugiere que el modelo de la hipótesis se ajusta igual de bien que el modelo saturado. En este caso, el p-valor es menor a 0,01, lo que indica que el modelo no se ajusta perfectamente a los datos.
CFI/TLI: Estos son índices de ajuste comparativo que comparan el ajuste del modelo de la hipótesis con el de un modelo nulo. Valores por encima de 0.90 suelen considerarse aceptables, y por encima de 0.95 muy buenos. En este caso, el CFI es 0.936 y el TLI es 0.92, lo que sugiere que el modelo se ajusta razonablemente bien a los datos, aunque podría ser mejor.
RMSEA: Es una medida de ajuste absoluto que indica el error de aproximación en el ajuste del modelo. Valores por debajo de 0.05 se consideran buenos, y por debajo de 0.08 aceptables. Aquí, el RMSEA es 0.055, lo que indica un ajuste aceptable.
Variables Latentes (Latent Variables): Esta parte muestra los resultados para las variables latentes del modelo, que son “SM (Salud Mental)” y “SEG (Seguridad)”. Para cada variable latente, se proporcionan los coeficientes de las relaciones entre la variable latente y las variables observables correspondientes (como sm_1, sm_2, etc. para “SM” y seg_1, seg_2, etc. para “SEG”). Las estimaciones son los coeficientes de carga factoriales que indican cuánto de la varianza de cada indicador es explicada por el factor latente. Los valores p (P(>|z|)) indican si cada coeficiente de carga factorial es significativamente diferente de cero.
La sección de regresiones muestra los efectos de varias covariables sobre la salud mental (SM). Cada coeficiente muestra cómo cambia la puntuación esperada de la sintomatología depresiva (SM) en desviaciones estándar con un cambio de una desviación estándar en la variable correspondiente, manteniendo constantes todas las demás variables.
qaut (Quintil de ingreso autónomo): La estimación es -0.036, lo que indica que un aumento de una desviación estándar en el quintil en el ingreso autónomo está asociado con una disminución en la sintomatología depresiva. Es decir, a medida que aumenta el ingreso autónomo de los encuestados, tienden a tener menos síntomas de depresión. El valor p<0,001 sugiere que este efecto es significativo.
zona (Urbano/rural): El coeficiente para la zona es -0.005, lo que indica que los encuestados en zonas rurales tienen una puntuación de sintomatología depresiva ligeramente más baja que los encuestados en zonas urbanas. Sin embargo, este efecto no es significativo (p = 0.763), lo que sugiere que no hay una diferencia significativa en la sintomatología depresiva entre los residentes urbanos y rurales en este estudio.
sexo: El coeficiente para el sexo es 0.186, lo que indica que, en promedio, las mujeres presentan una mayor sintomatilogía depresiva (con 0=masculino y 1=femenino ). El valor p<0,001 sugiere que este efecto es significativo.
edad: El coeficiente para la edad es -0.001, lo que indica que la sintomatología depresiva tiende a disminuir con la edad. Es decir, los encuestados mayores tienden a tener menos síntomas de depresión que los encuestados más jóvenes. El valor p de 0.001 sugiere que este efecto es significativo.
SEG (Seguridad ciudadana percibida): La estimación para SEG es -0.100, lo que sugiere que un aumento de una desviación enstándar en la percepción de seguridad ciudadana en el barrio está asociado con una disminución de 0,1 desviaciones en la sintomatología depresiva. El valor p<0,001 indica que este efecto es significativo.
maltrato (Percepción de haber recibido maltrato): El coeficiente es 0.162, lo que indica que en promedio los encuestados que perciben haber recibido maltrato con mayor frecuencia tienen una mayor sintomatología depresiva. El valor p de 0.000 indica que este efecto es significativo.
social (Satisfacción con la vida social): La estimación para social es -0.126, lo que sugiere que un aumento en la satisfacción con la vida social está asociado con una disminución en la sintomatología depresiva. El valor p<0,001 indica que este efecto es significativo.
# Crear una tabla de resultados en formato APA
semTable(ajus_sem, type = "html", paramSets = c("loadings", "slopes", "latentcovariances",
"fits", "constructed"), file = "resultados_sem")
| Model | ||||
| Estimate | Std. Err. | z | p | |
| Factor Loadings | ||||
| SM | ||||
| sm.1 | 1.00+ | |||
| sm.2 | 1.11 | 0.02 | 64.09 | .000 |
| sm.3 | 1.03 | 0.02 | 59.51 | .000 |
| sm.4 | 0.86 | 0.02 | 52.40 | .000 |
| SEG | ||||
| seg.1 | 1.00+ | |||
| seg.2 | 1.01 | 0.01 | 81.51 | .000 |
| seg.3 | 0.85 | 0.01 | 65.60 | .000 |
| seg.4 | 0.46 | 0.01 | 47.44 | .000 |
| Regression Slopes | ||||
| SM | ||||
| qaut | -0.04 | 0.00 | -7.96 | .000 |
| zona | -0.01 | 0.02 | -0.30 | .763 |
| sexo | 0.19 | 0.01 | 15.00 | .000 |
| edad | -0.00 | 0.00 | -3.26 | .001 |
| SEG | -0.10 | 0.01 | -14.86 | .000 |
| maltrato | 0.16 | 0.01 | 27.81 | .000 |
| social | -0.13 | 0.01 | -21.82 | .000 |
| Fit Indices | ||||
| χ2 | 2068.19(61) | .000 | ||
| CFI | 0.94 | |||
| TLI | 0.92 | |||
| RMSEA | 0.05 | |||
| +Fixed parameter | ||||
Aquí usamos semTable() para generar una tabla con los resultados principales del modelo.
# Mostrar la tabla de resultados en un navegador
browseURL("resultados_sem.html")
Aquí utilizamos browseURL() para abrir el archivo HTML generado en el navegador por defecto. Es una manera eficaz de visualizar la tabla de resultados.
# Diagrama del modelo de ecuaciones estructurales
semPaths(ajus_sem, # modelo ajustado
what = "std", # mostrar cargas estandarizadas
label.cex = 1, edge.label.cex = 1, # tamaño de las etiquetas y caracteres
residuals = FALSE, # no mostrar residuos
edge.color = "black") # color de las flechas
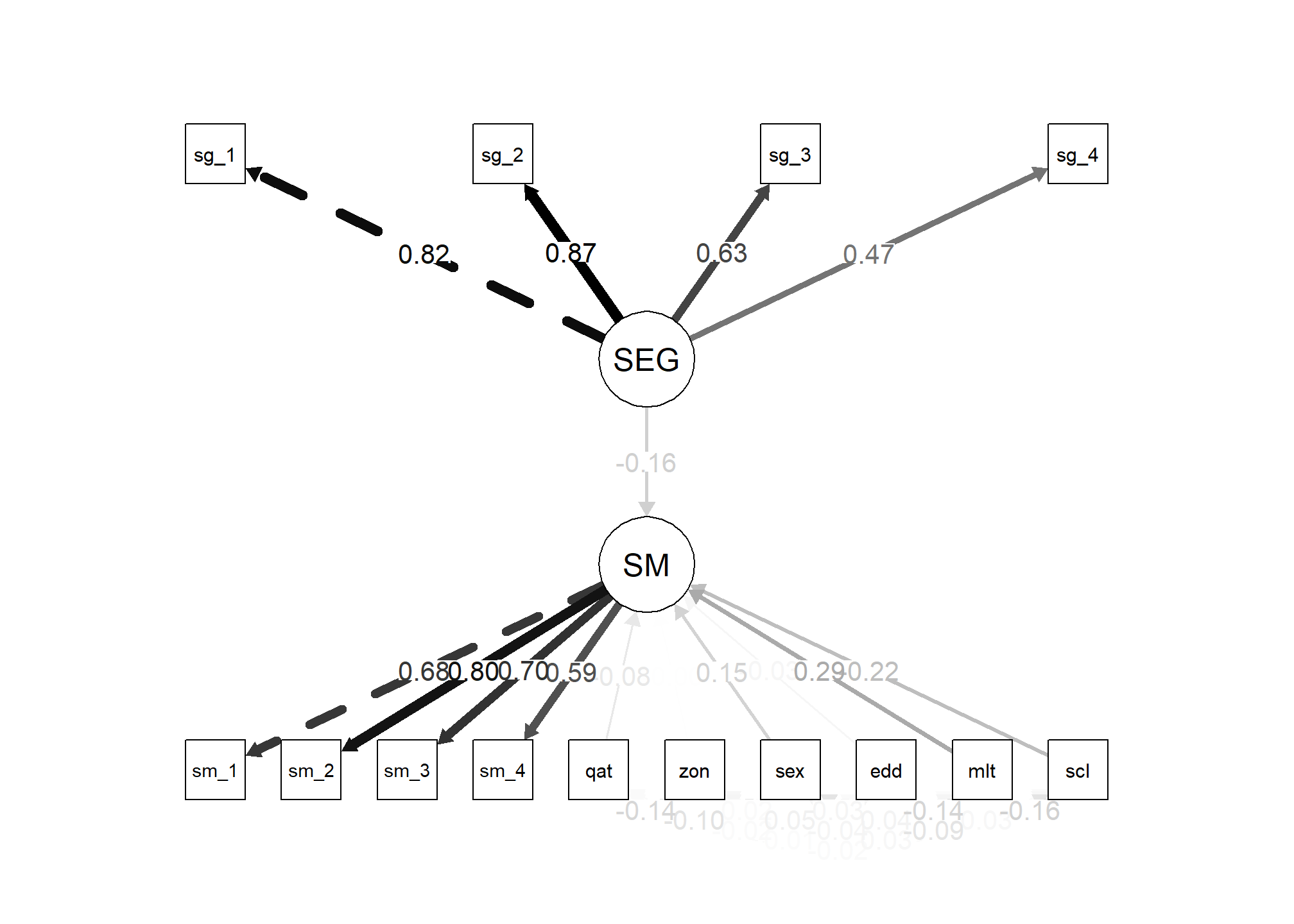
Aquí usamos semPaths() para generar un diagrama del modelo de ecuaciones estructurales que hemos ajustado. Los argumentos de esta función son similares a los que hemos usado antes. ajus_sem es el modelo ajustado, what = “std” indica que se deben mostrar las cargas estandarizadas en lugar de las no estandarizadas, label.cex = 1 y edge.label.cex = 1 controlan el tamaño de las etiquetas y de las flechas respectivamente, residuals = FALSE indica que no se deben mostrar los residuos en el diagrama, y edge.color = “black” establece el color de las flechas a negro.
Este diagrama proporciona una representación visual del modelo de ecuaciones estructurales que hemos ajustado, lo que puede facilitar su interpretación. En el diagrama, las variables observables se representan como rectángulos, las variables latentes como óvalos, y las relaciones entre variables como flechas. Las cargas factoriales o coeficientes de las rutas se representan junto a las flechas correspondientes.